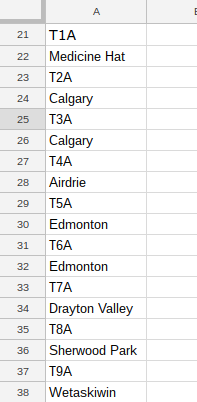I’m a not-so-secret spreadsheets nerd. I’m even in a sort of Spreadsheets Interest Group. The number of passionate people there tells me we’ve all relied on a good old spreadsheet at some point in our careers.
Even in this realm, Google Sheets are something of a superhero. Google Sheets spreadsheets can dynamically collect information for you while you sleep, and grab anything you want (stock prices, site analytics, and much more) from anywhere.
But what if you want to grab data from the web at large—perhaps to copy info from a table on a website? Maybe there’s a list of events, a grid of facts, or email addresses scattered around a webpage. Copying and pasting them would take forever—but Google Sheets has a better option.
You can import data from any web page using a little function called ImportXML, and once you master it you’ll feel like a certified Sheets Wizard. ImportXML pulls information from any XML field—that is, any field bracketed by a and a . So, you can grab data from any website and any metadata generated by any website, anywhere. Sure, you could copy-paste and then spend hours editing everything by hand, but why not automate the boring stuff?
Let’s do just that.
XML and HTML Basics
You’ll need to know some very basic HTML—or rather, the XML markup that designates sets of data in a webpage—to grasp the common functions here, so here’s a crash course. In essence, any set of and —the core building-blocks of a web page’s source code—mean that a certain set of data is contained inside them (perhaps like this). The of a page will have some text in a
aragraph, sometimes containing old text and perhaps a link (followed by .
to close it all out).
Google Sheets’ ImportXML function can look for a specific XML dataset and copy the data out of it.
So, in the example above, if we wanted to grab all the links on a page, we’d tell our ImportXML function to import all information within the tags. If we wanted the entire text of a web page because we were doing some more advanced text-mining work, we’d probably start by grabbing everything within the
or everything within every instance of
, and then clean up our data in stages after that.
If we told ImportXML to grab links from the example above, we’d get the text "a link." That might not be very useful, but at least you get the idea.
Tip: Want to dig a bit deeper into HTML and XML? Check out our Inspect Element tutorial to see how you can change anything on any web page by editing its code in your browser.
How to Extract a List of Postal Codes and City Districts
One of my current projects involves matching my customer list by their postal code to a municipal ward in my city. This is a fairly small project, since I’m only using a handful of downtown wards, but somewhat difficult, because in Canada there’s no dataset of our postal codes. No, really—Canada Post sued someone once for publishing a list of all the postal codes.
Luckily, some enterprising individual has put up a next-best version on Wikipedia: a table of postal codes followed by municipalities and neighborhoods it contains.
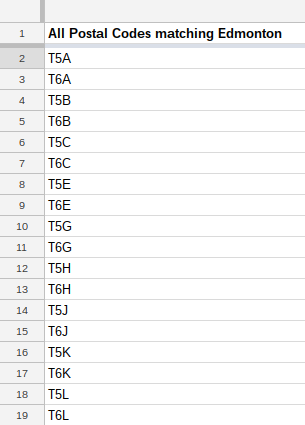
Wikipedia tables are a great way to practice ImportXML. Let’s try grabbing all the postal codes in Edmonton, Alberta. We’ll go to the "AB" chunk of the postal system, the ones that start with T. Open that page in a new browser window to follow along with this exercise.
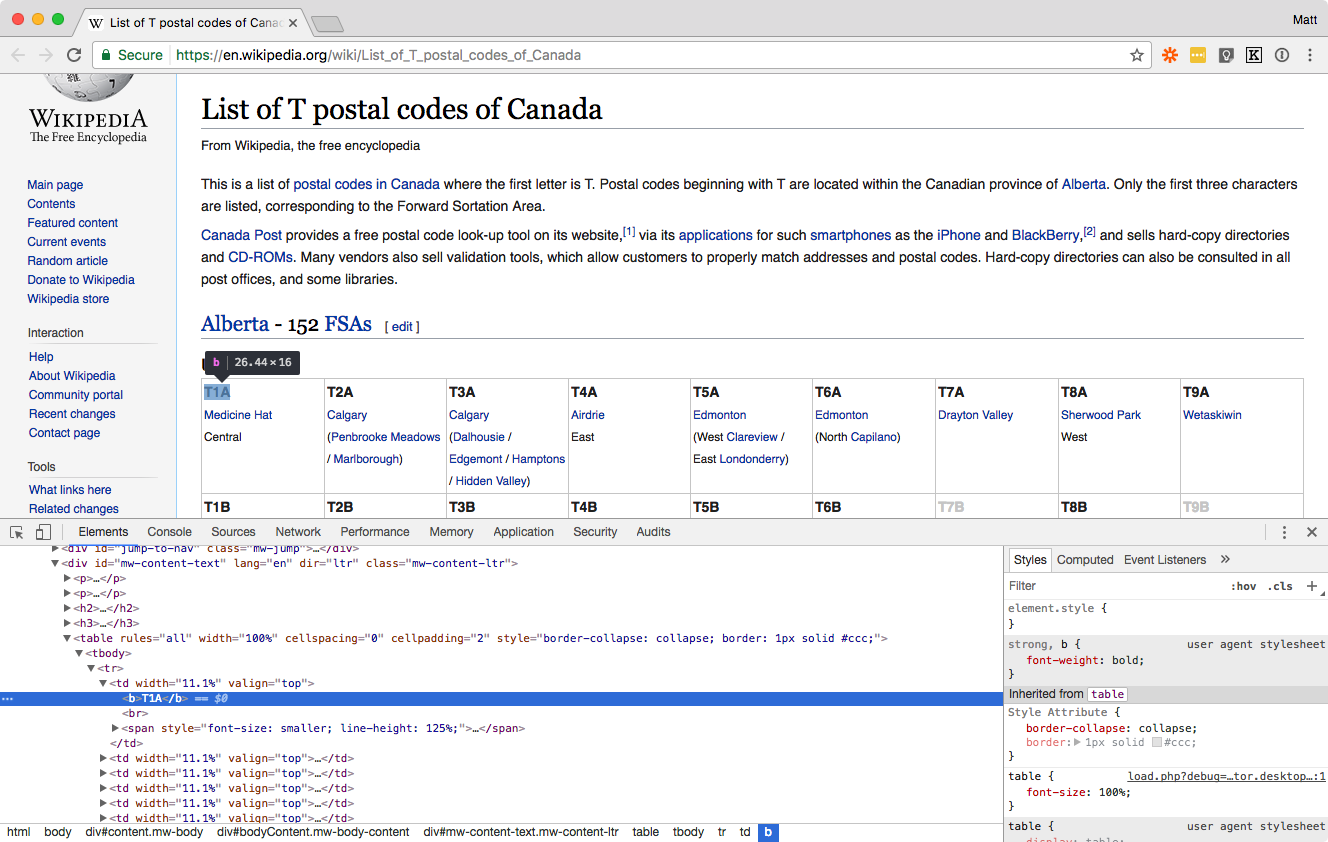
Let’s take a look at the page source. Select one of the postal codes, right-click on it, and select Inspect to open your browser’s tool to view the page’s source code.
It looks like each postal code is contained within a tag (which defines a cell in the table). So we’ll be importing all TD tags that contain the word "Edmonton" in them.
For your first lesson, create a new, empty Google Sheets spreadsheet. We’ll grab all the contents of the TD tag, including the and the links, by specifying what we want using XPath syntax. ImportXML takes the URL and the tags you’re looking for as arguments, so entering this in Google Sheets:
Looking back at our page source, we see that the postal code is in bold, or , and the city names that link to Wikipedia articles are, of course, in . Let’s try to grab only the first link in each cell, which is the major city, and ignore the other links, which are neighbourhoods. Modify that into two commands, in columns A and B -
This should give you an idea of how the syntax of the XPath query works: a tag with [1] means "only give me the first instance of inside ." So, td/span/a[1] gives you the first link inside the inside each
. In the same way, td/b[1] gives you the very first bold text inside each
—or just the postal code in our case.
A neat thing you can do is make two queries out of one function. So, we can combine these two requests with a | (pipe) symbol in the middle:
However, you won’t get the same result as before: it’ll interfile all the matching requests into one long list, instead of two columns. There are lots of uses for this, but not for our purposes here.
Besides, we don’t want all of these rows; we want only the ones that match "Edmonton" in that td/span/a[1] field. Remember that we want to return the postal code, so we want the b[1] of every
that has "Edmonton" in span/a[1]. Still with me?
To select only the postal codes in the boxes where the first links are ‘Edmonton’, we'll use this code:
We put the "search" part—the qualifying text that narrows down our results—within the [square brackets], without disturbing the path that actually delivers results. Voila!
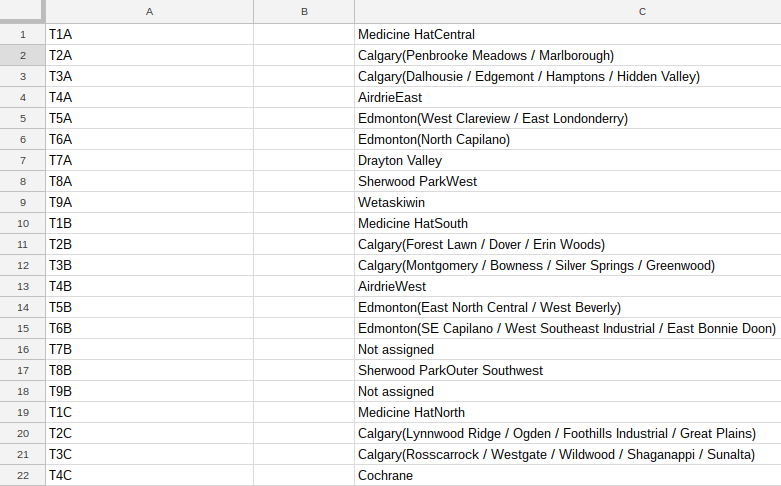
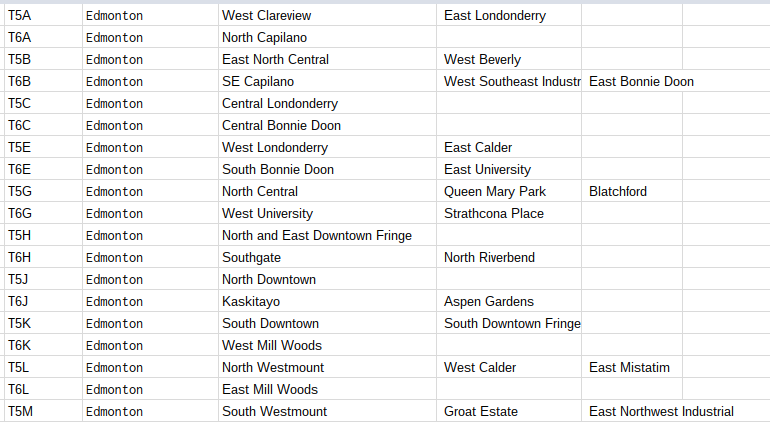
Now we want those neighborhood names. We write a matching importXML function to go in the next column, grabbing the text that comes after the word "Edmonton."
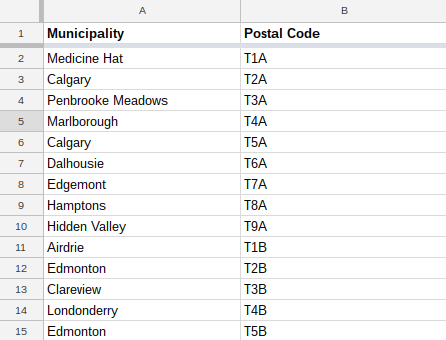
My solution grabs the entire content of span[1] and uses the parentheses and the slash to divide up content, slicing "Edmonton" into the first column and each neighbourhood name into later columns. From this two-step process we can match up postal codes and neighborhood names:
And then, a few columns later use the split and concatenate functions to separate and group the data we're working with:
=SPLIT(concatenate(B2:J2),"(/)")
That gives us our final, cleaned up table with just the postal code, city, and neighborhood info we need:
If you’re getting the hang of it, you can improve upon this method. Think about calling only the contents of after the a[1], or only the text inside parentheses, or everything not including the "Edmonton" string, or everything after the line break .
How to Automatically Copy Email Addresses from a Website
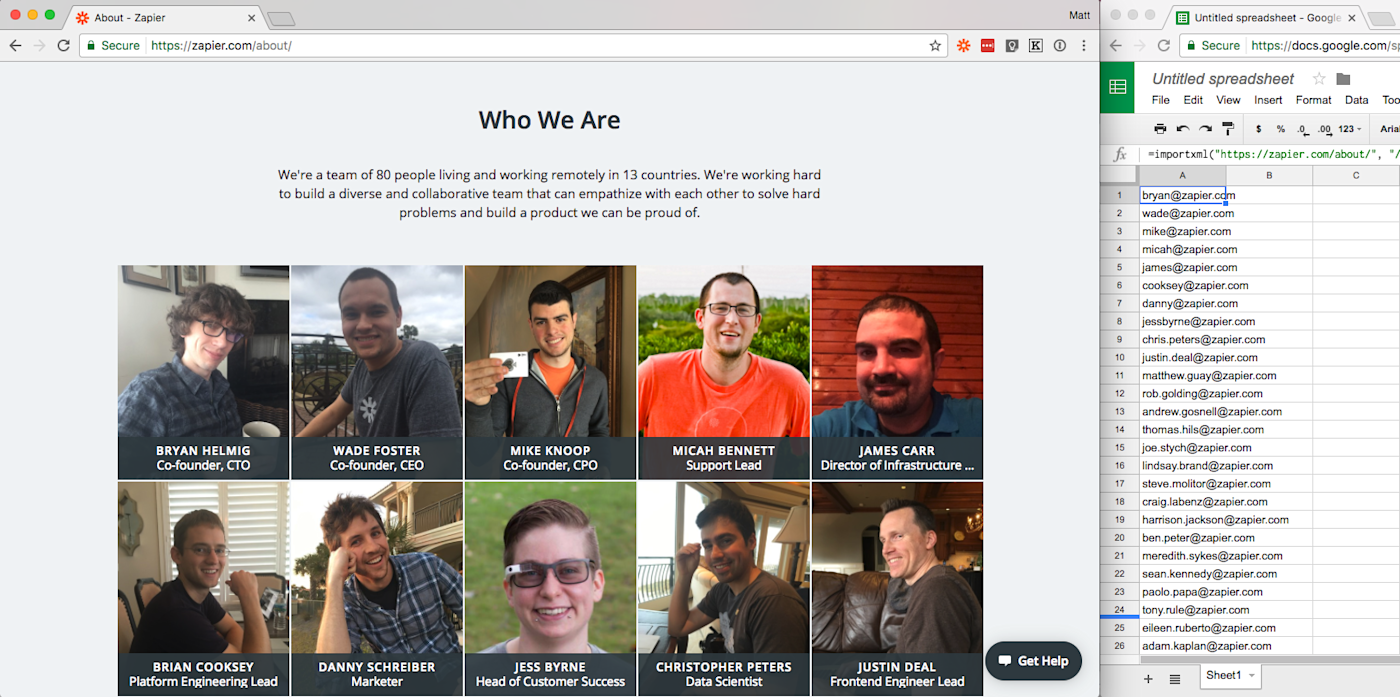
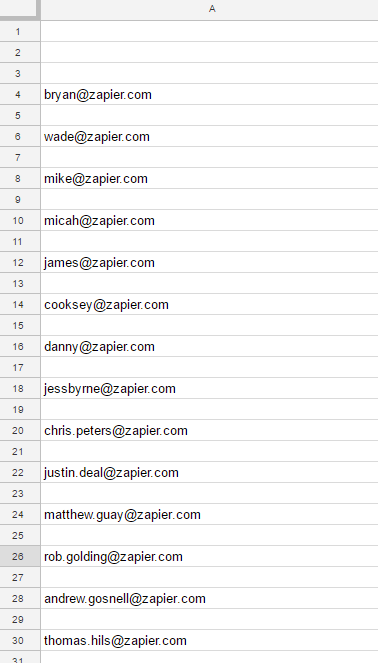
This one’s easy: Can you pull all of the Zapier staff emails from the About page?
Looking at the source code should tell you right away: Every email address of every Zapier team member is in a field with a class="email". Easy! When you want to specify an attribute of a tag (say, the "href" in an , or the "id" or "class" of a
Grabbing an email without shortcuts like these can be done. We do it by matching their essential form (username@host.suffix, aka bob@gmail.com). It’s more complicated, but has much more potential.
A regular expression is what we use to categorically capture information matching a certain format. Say we wanted to know all the temperatures listed on a weather website. We would capture that by saying "give us all the numbers that come before the symbol ° or ℃ or ℉"—yes, those are all different unicode characters.
If we wanted to grab a list of emails, we’d say "give us all the strings that fit the format username@host.suffix." Or, in a regular expression:
Take a deep breath, and we’ll walk through this step by step. You can see the @ symbol, and you can see that the "username" space before the @ (or [a-zA-Z0-9_.+-]+) is pretty close to the "host" area after the @ (or [a-zA-Z0-9-.]+).
And the "suffix" bit looks similar, but not quite. That’s because the characters allowed in an email address and in a hostname, as determined by the Gods Of The Internet, are limited. You may remember signing up for an email address and getting an error message when you tried to put "~~f41ry~~" in it. I, too, know that pain. That’s because emails take lowercase characters (a-z), uppercase characters (A-Z), numbers (0-9), underscores (_), dashes (-), and periods (.)—and, occasionally, plus signs (+).
What’s with the slashes and plus signs in that expression? Dashes and periods already signal specific things in regular expressions, and so to signify "the character dash and not the regular-expression function dash" we have to "cancel" them, which is a fancy term for "ignore what you’d usually do in this scenario." Cancelling is done by putting a backslash () in front of it.
The plus sign outside the brackets means "allow a character that matches that, one or more times." So, your email name can be any number of characters long, as long as it’s least one.
Then we do it again for the hostname: One or more characters of lowercase, uppercase, numbers, underscores, dashes, and periods—because some email addresses are "@mail.hostname.suffix".
The last bit, the suffix is more restricted: ([a-zA-Z0-9-]{2,15})
We can only have simple characters, and we can only have 2 to 15 characters (to include all the new hot trendy domains like .coffee and .gripe and, the apparent longest so far, .cancerresearch). So, instead of the + that means "any length," we set a minimum and maximum length with {2,15}. (You can set something like "exactly five" with just {5}.)
To recap, when we want one character alone (as in the @) we just type that. When we want a character that fits any of several character types, we throw the acceptable characters all together inside square brackets. When we want to multiply that by some number, we add on some squiggly brackets defining minimum and maximum numbers of characters matching the description, or use indicators to say "one or more" or "none or more." When we’re doing multiplication like that, we throw it in plain brackets. Some characters require "cancelling" with a backslash.
There, you learned a powerful new skill today! All just to grab emails. Whew.
Different programming languages use different symbols and syntax to make things work; for a small taste, check emailregex.com—yes, an entire website just for ways to look for an email address (don’t read the comments). And if you want to dig even deeper into Google Sheets' regex, here's a special secret Google Sheets list of functions - secret because Google is infamously bad at documentation, so a bunch of users have written their own guides through trial-and-error.
How to Use Regex to Import Email Addresses From a Website in Google Sheets
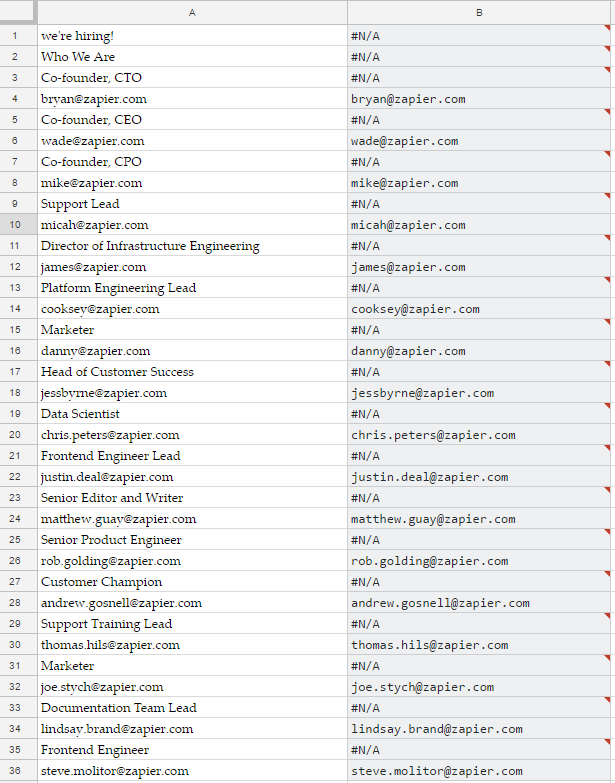
Let’s grab those Zapier addresses using our newfound regex powers. We’re importing the same s, but instead of looking for a class that equals "email" we’re looking for content that matches the regular expression. Again, let’s do it in two steps: we’ll call lots of information from the Zapier page in the first column, then sort through those for emails in the second column.
Can you combine these two functions? Remember, ImportXML will fill out columns and rows all by itself, depending on what it finds (called an array formula), and the regex query has to be filled out for each cell you want a result in (that is, not an array formula). To throw them all together, you simply command Regexextract to be an array formula just this once (and throw in an IFERROR for decency's sake, to leave cells blank where no email address can be found):
And, with that, here's our finished Regex-powered list of email addresses from Zapier's About page:
Become a Google Sheets Expert with Zapier
For further reading, we’ve written about other webscraping in our free Spreadsheet CRM eBook. You can also read about ImportXML’s cousin functions:
ImportHTML—a weaker function that will grab an entire table or list from a given webpage without any further controls
ImportRange—to grab data from other sheets in the spreadsheet
ImportData—to import data from a linked CSV or TSV file
ImportFeed—which works much like ImportXML, but to import RSS or Atom feeds, which can be great if you’re having problems importing XML from a certain website (cough Twitter).
Along with that, you'll learn spreadsheet basics if you need to review, along with tips on how to build a full app in your spreadsheet, use Google Apps Script to automate your spreadsheets, and a guide to using Google Sheets' companion app, Google Forms.
Or, for an easier way to import data into your Google Sheets spreadsheet, you can use app automation tool Zapier's Google Sheets integrations to add data to your spreadsheet automatically. It can log Tweets to a spreadsheet, keep a backup of your MailChimp contacts, or save data from your forms and events to a sheet.
Zapier can also put your data to work. Say you use importXML to pull a list of email addresses into a spreadsheet. Zapier could then copy those from your spreadsheet, and send them an email message or add them to your mailing list. It could add a list of dates to your Google Calendar for an easy way to build a holiday or event list. Or it could add each new entry as a new task in your project management app—or much, much more.
Get productivity tips delivered straight to your inbox
We’ll email you 1-3 times per week—and never share your information.
Related articles
Improve your productivity automatically. Use Zapier to get your apps working together.